Technology
Differential Privacy: Balancing Privacy with Precision in the Data Age
Published on:
Sunday, August 4, 2024
By Hardik Katyarmal

In the physical world, privacy is something we can often manage by altering our appearance or behavior—think of celebrities like Tom Cruise, who might don a wig and sunglasses to go unnoticed while enjoying street food. But in the digital world, protecting our identities requires more sophisticated methods. This is where Differential Privacy (DP) comes into play, a technique that adds a controlled amount of randomness, or “noise,” to data, effectively masking individual identities while still allowing for meaningful analysis.
What is Differential Privacy?
Differential Privacy is a mathematical framework designed to enable the sharing of aggregate data while safeguarding individual privacy. The principle behind it is simple yet powerful: by introducing a precise amount of noise to data, it becomes nearly impossible for anyone to reverse-engineer the information to identify individuals. The noise is calibrated to ensure that while the individual data points are obscured, the overall trends and patterns remain intact and useful.
To understand this better, consider an example of querying a database to find the average salary of engineers at a company like Google. Even if names and other direct identifiers are removed, there’s a risk that the dataset could be analyzed in such a way that individual identities could be inferred, especially if the salaries are unique. Differential Privacy steps in by adding noise to the salary data. This noise is carefully calculated based on the sensitivity of the query, which measures how much the result would change if a single data point were added or removed. The result? You can still compute the average salary with reasonable accuracy, but the privacy of individual salaries is maintained.
How Does Differential Privacy Work?
The core idea of Differential Privacy is to ensure that the presence or absence of a single individual’s data in a dataset does not significantly change the outcome of the analysis thus making sure no attackers can deterministically figure out if a particular record was present in the data. Differential Privacy can be characterised by the following:
Consistent But Noisy Results: Since noise is added each time a query is run, the results will be similar but not identical on repeated runs of the same query. For instance, the average salary might be $100,208 in one run and $100,310 in another—close enough for most analyses but different enough to protect individual identities.
Testing on Near Identical Datasets: To test whether an algorithm is Differentially Private or not, we have to test it on two datasets (D1 and D2) which are almost identical except for one individual's records. Eg: Dataset D1 includes your salary, and D2 doesn’t.
Probabilistic Guarantees: The results are expressed in terms of probabilities. For example, the probability that the average salary is within a certain range might be given as 0.1. This probabilistic approach is central to the privacy guarantees that Differential Privacy offers.
The Mathematical Foundation
Differential Privacy is underpinned by a formal mathematical definition involving a privacy loss parameter, ε (epsilon), and a secondary parameter, δ (delta).
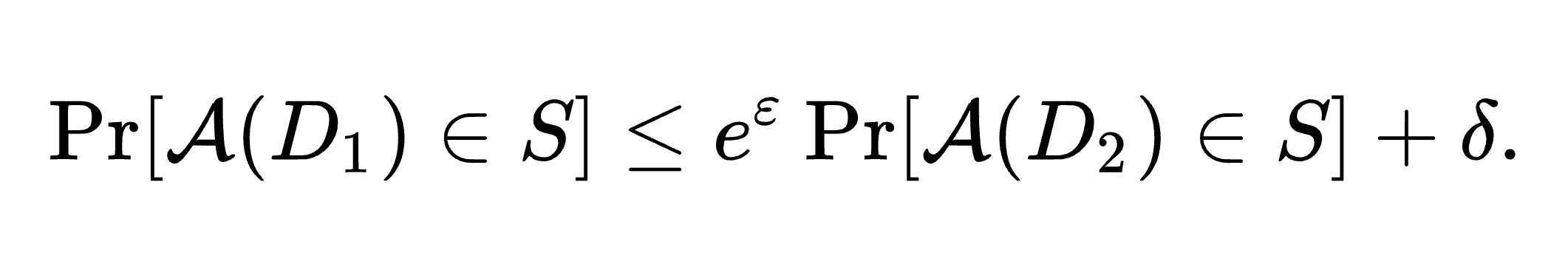
The parameter ε quantifies the maximum allowable difference in the probability of an outcome when one individual’s data is included versus when it is not. This parameter allows organizations to balance the trade-off between privacy and data utility—lower values of ε provide stronger privacy but may reduce the accuracy of the data, and vice versa. Eg: If D1 probability is 0.1 and ε is 0.2, RHS probability will be bounded within 0.1 x e^0.2, that is 0.122.
The addition of δ accounts for the fact that privacy guarantees may not hold in extremely rare cases, providing a way to quantify the exact risks of privacy loss.
Why Differential Privacy is Special
Differential Privacy stands out among privacy-preserving techniques for several reasons:
Robust Privacy Guarantees: Unlike older methods that often rely on anonymization or aggregation, Differential Privacy ensures that the presence or absence of any single individual’s data has a minimal impact on the analysis outcome. Implying whether an attacker wants to re-identify someone, determine if they are in the dataset, or deduce sensitive information to the row level, Differential Privacy provides a strong and comprehensive privacy guarantee.
Resilience: Differential Privacy is resilient to attacks, regardless of what an attacker may already know about the dataset or individuals in it. This makes it a powerful tool for protecting privacy, even against sophisticated attempts to de-anonymize data.
Quantifiable Privacy Loss: By using the parameter ε, Differential Privacy allows organizations to make formal, mathematically sound statements about the level of privacy they are providing. This makes it easier to balance privacy and data utility in a controlled manner.
Composability: Differential Privacy supports the composability of multiple processes, meaning that the overall system retains its privacy guarantees even when differentially private processes are combined. This is particularly useful for complex data usage scenarios, such as publishing statistics, training machine learning models, or releasing anonymized datasets.
The Origins and Evolution of Differential Privacy
The concept of Differential Privacy was first introduced in 2006 as part of a groundbreaking research effort that sought to address the limitations of existing privacy-preserving techniques. The original research defined the formal framework for Differential Privacy and introduced the parameters ε and δ. This work laid the foundation for the development of Differential Privacy algorithms, such as the Laplace mechanism, which adds noise drawn from a Laplace distribution to query results based on the sensitivity of the data.
Since then, several repositories and tools have been developed to facilitate the implementation of Differential Privacy. Notable examples include PyDP and PySyft by OpenMined, as well as Google’s open-source Differential Privacy library. These tools have made it easier for organizations to apply Differential Privacy in practical settings, ensuring that the benefits of this powerful technique are accessible to a wider audience.
Real-World Applications of Differential Privacy
Differential Privacy is one of the most application-ready privacy technologies available today, with a growing list of real-world use cases:
Machine Learning: In the era of AI, organizations need diverse data sources for exploratory data analysis. Differential Privacy enables the use of sensitive datasets that were previously out of reach, ensuring that individual privacy is protected even as insights are extracted.
Publishing Statistics: The U.S. Census Bureau uses Differential Privacy to protect the confidentiality of respondents. By adding noise to the data, they can publish aggregate statistics that are useful for policy-making and research without compromising individual privacy.
Consumer Insights: Differential Privacy allows companies to share high-level insights about their users with partners, such as in marketing or supply chain management, without the risk of identity leakage.
Conclusion
In a world where data is the new oil, protecting individual privacy while extracting meaningful insights is more critical than ever. Differential Privacy offers a powerful, mathematically sound approach to achieving this balance. By adding just the right amount of noise to data, it ensures that organizations can continue to innovate and derive value from data without compromising the privacy of individuals.
Who would have thought that a sprinkle of randomness could be so powerful? Yet, here it is, offering a robust solution to the privacy challenges of the digital age.
#DataPrivacy #DifferentialPrivacy #MachineLearning #PrivacyTechnology
Explore more on how Differential Privacy is shaping the future of data analysis and privacy protection on our blog. Stay informed with the latest developments and best practices.

